Unpacking Observability: The Observability Stack

As the manager of the Observability team at my current company, I find myself in a rather unique position. As part of my job, I get to define the “golden path” of Observability here. This means building an Observability practice, promoting the use of OpenTelemetry (OTel) and Observability-Driven Development (ODD), and defining a Observability stack for teams across the org to use.
Our current Observability stack looks like a bit of a rummage sale of various open source products, as a result of Team X, being keen on using Tool A, and Team Y being keen on using Tool B. We ended up with a stack that included a bunch of different tools cobbled together in the hopes of providing Observability. Having followed the Observability scene pretty closely for the last year or so, I was pretty sure that we could reduce this stack by a LOT.
But first, I needed to start with some basics.

The Plan
I think that before even talking about Observability tooling, it’s important for an organization to first understand Observability and the problem that it solves.
Recap: Observability lets us understand a system from the outside, by letting us ask questions, without knowing the inner workings of that system. Observability lets us deal with unknown unknowns.
This can be a challenge, because most organizations are steeped in the old Application Performance Management (APM) tradition. This is further muddled by the fact that many APM vendors have re-branded themselves as Observability vendors, in the same manner that many companies have re-branded Operations roles as DevOps or Site Reliability Engineer (SRE). 🤮
Embracing Observability means unlearning APM.
Is APM bad? No, it isn’t. But it’s not well-suited to the microservices world, whereas Observability is.
I’ve spent a lot of time educating myself on modern Observability practices: reading blog posts, watching videos, attending o11ycon, and binging on the o11ycast podcast. Of equal importance was sharing these resources with my own team, to ensure that we’re all aligned. After all, we’re on a mission to educate an entire organization on Observability benefits and practices.
When it comes to sharing info across an organization, it’s unreasonable to ask folks to go through so much material. They ain’t got time for that. They want the Coles Notes¹ version, not the 1000-page novel. So I put together a couple of intro blog posts on Observability. Education is key. And when people get it, you get buy-in. ✨ 🌈
But that was only the beginning. With a better grasp on Observability, I was ready to start thinking about what our stack should look like.
The Observability Stack
If there’s anything that’s an absolute must in my Observability to-do list, it’s getting org-wide acceptance of OpenTelemetry (OTel) for data-collection. OTel is great for application instrumentation (capturing traces — including spans and events — from our software) and metrics (recording and transmitting readings from our infrastructure). I chose OpenTelemetry because it is:
- THE industry standard for data-collection ✅
- Vendor-agnostic ✅
- Supported by the major Observability vendors ✅
I want to get rid of most — if not all — of the mish-mash of tools that I listed in the intro, and I strongly believe that using OTel along with an Observability back-end will give me everything that I need.
A few noteworthy requirements:
- For my Observability back-end, I wanted to go with a vendor solution. Vendors provide nice all-in-one solutions so that you can focus on Observability itself, and not on stitching tools together. I also really didn’t want the headache of managing tools on-prem if I didn’t need to.²
- I don’t want to use Prometheus. I think that we can pull this off. Turns out that Prometheus refers to both the Prometheus tool and the Prometheus data format. (Confusing, right?!) If I’m going with an Observability vendor, I certainly don’t need/want to maintain the Prometheus tool. And if I have any infrastructure that captures Prometheus-style metrics, I’m hoping that OTel can come to the rescue for me (more on that below).
After a few weeks poking around, asking the mighty Google, and asking lots of questions to folks in the Observability community,³ I came up with the diagram below. I’m happy to say that it has been vetted by some legit folks in the Observability community, so this isn’t some unrealistic pipe-dream.
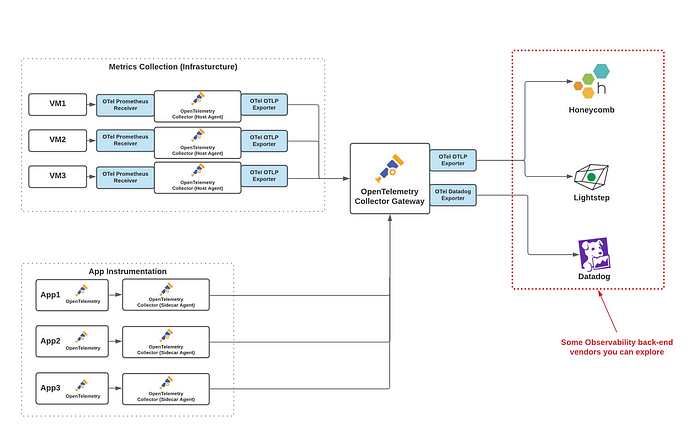
Thanks to its vendor-agnostic amazingness, I can then send my data to whatever vendor back-end I choose. And if I’m unhappy with one vendor, I can switch to another without much effort.
Let’s take a deep-dive into the key aspects of my proposed architecture.
Note: The OpenTelemetry Collector features prominently in the diagram above. I’ll cover that in greater detail below.
Observability Back-End
Before I continue, it’s important to point out that yes, I have listed three Observability vendors above. Because…why not! The beauty of OTel is that you can totally do this! Also, this is a great way to evaluate vendors.
Your end goal should be to use a single vendor that best embodies the practices and principles of Observability.
What makes a good Observability vendor? Some things to consider:
- Speaks o11y fluently. This may seem a little too abstract, but you can tell the fakers from the real-deal by how they speak about Observability. For one thing, they don’t talk about APM or the “Three Pillars”. They ensure that you, as a potential customer, understand the definition of Observability, and, equally-important, they recognize the paradigm shift required when going from APM-land to Observability-land. They focus on unknown-unknowns as a first-class citizen.
- Supports OpenTelemetry…properly. By “properly” I mean that the vendor doesn’t just say that they support OTel. They actually have a good understanding of OpenTelemetry and can provide guidance on using OTel with their product.
- Promotes dynamic dashboards. Dynamic dashboards help with the unknown unknowns, by letting you drill down and ask questions about your system, so that you can get to the root of your issue(s). These are different from the traditional static dashboards, which answer a question that someone asked once upon a time. They’re fine for dealing with known unknowns, and some may still be useful. Others may be relics of an older, irrelevant codebase.⁴
- Facilitates easy troubleshooting of prod issues. One of the key promises of Observability is that it allows you to get to the bottom of prod issues relatively quickly and easily, without necessarily having super-deep system knowledge.
- Supports high-cardinality. Cardinality refers to the number of unique values in your data set. If you have high cardinality, you have a large number of unique values (e.g. Customer ID, IP address, Social Insurance Number). If you have low cardinality, you have a small number of unique values (e.g. gender, country). According to New Relic’s John Withers, “High-cardinality data provides the necessary granularity and precision to isolate and identify the root cause, enabling you to pinpoint where and why an issue has occurred.”
- Has a good community. I believe that having a good support community is important from a vendor. Maybe because I’ve been spoiled by good community support. I want a vendor that has a community Slack where I can ask questions, occasionally even contribute, and won’t be met with a “please open a ticket” response to my questions.
- Doesn’t break the bank. This is the big ‘ole elephant in the room. Of course these services don’t come for free, and yes, if I wanted free, I’d probably be looking at cobbling together my own o11y stack from a bunch of open source tools. That said, I don’t want to break the bank on an Observability vendor, and to do so, it’s important to know how a vendor charges its customers, and it’s important to try to surface those sneaky additional costs that creep out of the woodwork when you start using a product for realzies. Finally, it’s important to understand what level of visibility is offered for that cost, because a pre-aggregated metrics provider may be cheap, but it doesn’t actually meet the critical requirements.
Instrumentation
When you instrument your code with OpenTelemetry, you can do so in one of two ways:
- auto-instrumentation: Uses shims or bytecode instrumentation agents to intercept your code at runtime or at compile-time to add tracing and metrics instrumentation to the libraries and frameworks you depend on. The beauty of auto-instrumentation is that it requires a minimum amount of effort. Sit back, relax, and enjoy the show.
- manual instrumentation: Requires adding spans, context propagation, attributes, etc. to your code. It’s like commenting your code or writing tests.
Auto-instrumentation is already available for a number of languages (and for a number of popular frameworks/libraries for these languages), including Java, .NET, Python, Ruby, JavaScript, Golang.
So you may be wondering: when should you auto-instrument, and when should you manually instrument? Should you choose one over the other? How can they best be combined when the language — or framework — supports it?
Start with auto-instrumentation if it’s available. If the auto-instrumentation isn’t sufficient for your use case, then add in the manual instrumentation. For example, auto-instrumentation doesn’t know your business logic — it only knows about frameworks and languages — in which case you’ll want to manually instrument your business logic, so that you get that visibility.
OpenTelemetry Collector
If you’ve worked with observability vendors before, you may have noticed that they tend to have their own agents for receiving, processing, and exporting data from your apps and your infrastructure. This kinda sucks if you’re trying to avoid vendor lock-in. Fortunately, OpenTelemetry provides a vendor-agnostic agent called the OpenTelemetry Collector.
The OTel Collector can be deployed in two different ways:
- Agent: Runs as an application sidecar, binary on your host, or daemonset on your Kubernetes or Nomad cluster (or whatever container orchestration tech tickles your fancy). It collects host metrics automatically, and collects tracing information.
- Gateway: One or more Collector instances running as a stand-alone service in a cluster, environment, or region. It’s used for doing more advanced stuff, such as buffering, encryption, data obfuscation, and tagging. It receives data from OTel Collector Agents deployed within an environment.
You should have at least one OTel Collector in your architecture, because you need it to translate your metrics and your instrumentation data into a useful format that can be fed into your chosen Observability back-end. How many OTel Collectors you end up using in your own systems depends on your specific situation. You could have a bunch of Agents and no Gateway. Or a Gateway and no Agents. Or a Gateway and a bunch of Agents. Lots of options. Most likely you’ll want to go with a combo of Agents running on your hosts, some sidecar agents on your containers, and a Gateway cluster. How many nodes in your Gateway cluster depends on your particular use case.
The diagram below shows the architecture of the OTel Collector:
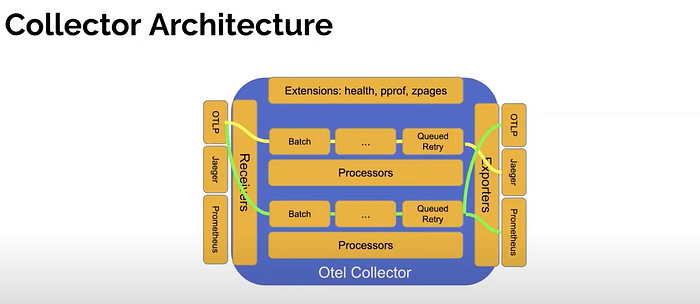
Let’s dig into what all this means!
The OTel Collector has 4 main components:
- Receivers
- Exporters
- Processors
- Extensions
Note: If you check out the OTel GitHub repos, you’ll notice the otel-collector and otel-collector-contrib repos. The contrib repo is for contributions that are not part of the core distribution. This does not mean that it is any less relevant or any less useful!
Receivers
The OpenTelemetry Collector’s receiver is used to get data into the OTel Collector. If you’re sending out instrumentation data from your application code, you would use the native OpenTelemetry Protocol (OTLP) format, which means that you’ll be using the OTLP receiver.
If you’re receiving metrics data from your infrastructure in some different data format (e.g. statsd, Jaeger, Prometheus), you’ll need to use a receiver that ingests that format to convert it to OTLP.
Note: I’m hoping that we can use the OTel Collector’s Prometheus Receiver to straight up replace running the Prometheus tool. My team is actually POCing this right now, and I expect to have an update in the next couple of weeks on the results of this experiment!
Exporters
The OTel Collector sends data to multiple back-ends by way of exporters. These translate OTLP to a vendor-specific back-end format. These include but are not limited to:⁵
- Datadog
- Dynatrace
- Jaeger
- Loki
There’s also an OTLP exporter, which doesn’t actually do any data transformation. Why do you need it? For things like:
- Configuring your Observability back-end (e.g. Lightstep and Honeycomb support OTLP and therefore would utilize the OTLP exporter)
- Defining pipelines (more on that below)
Processors
Processors can be used to transform your data before exporting it. For example, you can use processors to append/modify/remove metadata, filter data, or even obfuscate data. You can also use processors to help ensure that your data makes it through a pipeline successfully by batching data or defining a retry policy. This is just scratching the surface. Be sure to check the OTel docs for more on what Processors can do.
Extensions
For completeness, I’ll briefly mention the OTel Collector Extensions. They were mainly designed so that you can use them to monitor the performance and behaviour of the Collectors. You use them for health checks and profiling.
Dataflow (Pipelines)
You might be wondering how we define how data flows through the OTel Collector. This is done with pipelines. Pipelines define the flow of your traces (application data) and metrics (infrastructure data). For example:
- Trace pipeline: Receive instrumentation data via OTLP, run through some processors that add a couple of extra attributes, and then export the data to a Datadog back-end via the Datadog exporter.
- Metrics pipeline: Receive Prometheus-style metrics from your infrastructure, remove a few attributes that you don’t need, and export the data to a Lightstep back-end via the OTLP exporter.
Also, there’s nothing stopping you from receiving from multiple sources and exporting to multiple sources in a pipeline.
That’s all well and good, but how in Thor’s Hammer do we configure all this??Using YAML! Check out a sample here:
Note: For more OTel Collector config samples, go here.
A few things to note:
- We have a place to configure our
receivers,exporters, andprocessors. And we can configure more than one of each kind! - Pipelines are defined in the
servicessection. We have separate pipelines for traces (our application code), and for our metrics (our infrastructure)
Since we’ve already covered a lot here, I’ll leave a full-fledged OTel example for a later blog post. My point here is to give y’alls a basic high-level understanding of the OTel Collector and its magical capabilities.
Final Thoughts
That was a lot to take in! Take a breather…you deserve it!
Coming up with an Observability stack for my organization has been a journey. And a fun one at that. Regardless of what Observability stack you implement in your organization, you should consider the following:
- Educate your organization about Observability. Many folks will be coming from an APM background, so be prepared for pushback.
- Make OpenTelemetry a first-class citizen in your organization so that you’re not stuck with a back-end who turns out to be a poor fit for your org.
- Select an Observability back-end that supports OpenTelemetry and best encompasses the principles and practices of Observability. And stay clear of back-ends that still talk about APM.
- Consider going for an Observability vendor, rather than trying to string a bunch of open source tools yourself. The cost of maintaining these tools just ain’t worth it, yo.
I shall now reward you with a picture of some cows in a field.

Peace, love, and code.
Related Listening
Be sure to check out my guest spot on O11ycast, as I talk about Tucows’ Observability journey!
More from the Unpacking Observability Series
References & Resources
- A Next Step Beyond Test Driven Development
- The Three Pillars of Observability that Weren’t
- OpenTelemetry Agent and Collector CNCF talk by Steve Flanders and Trask Stalnaker (YouTube, 25:33)
- How the OpenTelemetry Protocol Works with Lightstep & Prometheus
- What are you doing for distributed tracing? (Reddit)
- Notes on the Perfidy of Dashboards
- OpenTelemetry automatic instrumentation: a deep dive
Acknowledgements
Big thanks to folks at Honeycomb and Lightstep for helping to clarify a number of the concepts covered in this post, and for putting up with my barrage of questions. ❤️
Footnotes
[1]: Coles Notes are the Canadian equivalent of CliffsNotes
[2]: That’s not to say that you can’t. If that’s your jam, then by all means, go for it!
[3]: Big shout-out to Honeycomb and Lightstep for a WEALTH of great info, including informative videos and blog posts. They also have a very responsive user community via the Honeycomb Pollinators Slack, and the Lightstep Community Discord. These two communities have aided me immensely in understanding OpenTelemetry better, and in vetting my ideas.
[4]: I highly recommend that you check out this comprehensive post on dashboards and Observability.
[5]: Check out the comprehensive list of OpenTelemetry Collector Exporters here (non-core distribution) and here (core distribution).

